


Foundation Models and Fair Use
A Review of the Article by Peter Henderson et al

While Lemly and Casey’s Fair Learning article considers whether the use of copyrighted works in the training of artificial intelligence (AI) or machine learning (ML) applications can be “fair use” under US copyright law, Prof. Lemley is also the co-author of Foundation Models and Fair Use, which looks directly at this fair use question with respect to the training of generative AI (GenAI) models.1
Lemley & Casey (2020) have pointed out that training a machine learning model on copyrighted data is likely considered fair use in circumstances where the final model does not directly generate content. For example, training a model on a corpus of popular books solely for predicting the similarity of two passages is transformative and likely falls under fair use. However, when it comes to training and deploying foundation models for generative use cases, the analysis becomes more complex. This is because these models are usually capable of generating content similar to copyrighted data, and deploying them can potentially impact economic markets that benefit the original data creators. For these scenarios, legal scholars argue that fair use may not apply…
The authors begin by analyzing the four fair use factors under § 1072 , beginning with transformativeness. One could be forgiven for wondering where “transformativeness” is in the four enumerated factors of § 107 because that word does not appear there. Although the Act refers to the “purpose and character of the use,” in Campbell v. Acuff-Rose Music, Inc.3 the Supreme Court in held that
The central purpose of [the first factor] is to see, in Justice Story’s words, whether the new work merely “supersede[s] the objects” of the original creation … or instead adds something new, with a further purpose or different character, altering the first with new expression, meaning, or message; it asks, in other words, whether and to what extent the new work is “transformative. (internal quotes omitted).
Since Campbell, in deciding whether use of a copyrighted work was fair use or infringement, courts have often focused their analysis on whether the new use was transformative.4 For example, in the 2021 case Google LLC v. Oracle America Inc.5, the Supreme Court found that Google’s copying of small portions of Java’s API in order to make it operable with Android phones was fair use because the copying transformed the code to make it interoperable with Android. Similarly, in the 2015 case Authors Guild, Inc. v. Google, Inc.6, the Second Circuit found that Google Books displaying small portions of books in response to user’s queries made Google’s copying of entire books transformative fair use. The authors summarize different types of transformation, with cites to potentially relevant fair use cases, as follows:
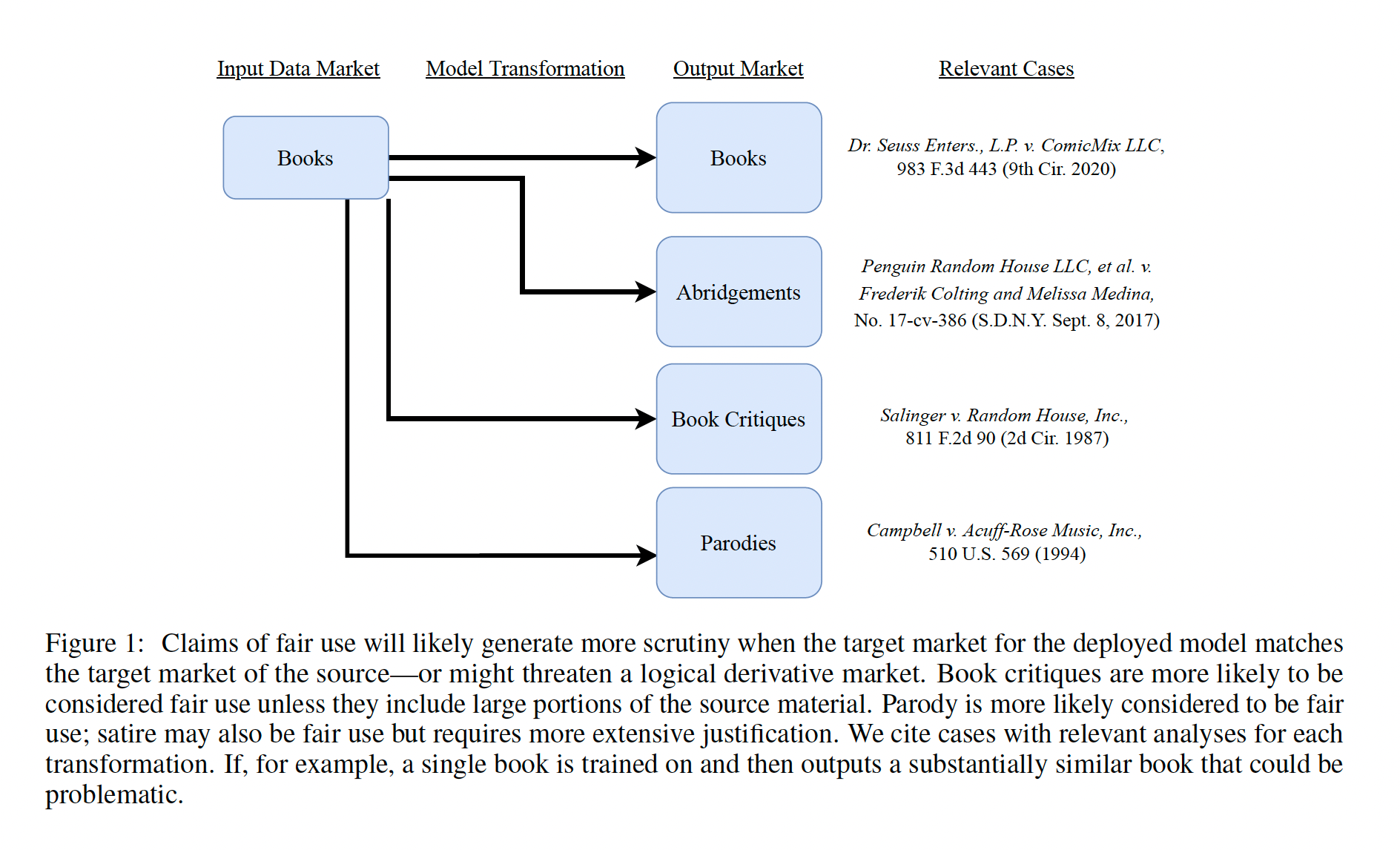
After noting the other 3 fair use factors (nature of copyrighted work, amount copied, and effect on market), the authors begin applying the fair use analysis to “natural language text generation” like GPT, focused on the GenAI output. They juxtapose Second Circuit’s Google Books case above with a district court case from the District of Arizona, in which the court found that “making small formatting changes and displaying books on the internet do[es] not constitute fair use” and asks the following hypothetical:

I agree that the initial condition described in the hypothetical is unlikely to be fair use. But I think I am more skeptical than the authors that the second condition could be fair use, primarily because I think one of the key findings in the Google Books case is that the use case discussed by the Second Circuit was scholarly; i.e., Google Books could assist scholars in researching texts in new and interesting ways. As noted in my review of the Fair Learning article, § 107 begins with a list of “purposes” for which the fair use exception may be appropriate, which include scholarship and research. Reading a child a bedtime story, while certainly transformative from the original printed text, does not deliver the same social benefit of scholarship that might justify the copying.
The authors also note that courts application of transformativeness is not always linear; i.e., one can’t simply look at the n-gram overlap.7 That is, it is not only how transformative the new work is, but what part of the original work is being transformed. To support this proposition the authors cite Dr. Seuss Enters., LP v. ComicMix LLC,8 in which the Ninth Circuit found that the reimagining of Dr. Seuss’ famous Oh the Places You’ll Go! as a Star Trek-infused version Oh the Places You’ll Boldly Go! was not fair use even though there was “a very small similarity ratio of 0.04 when using raw text overlap” because the court found that the “heart” of the original work was being copied, which might affect the market for the original.
Not only does the portion of the original work that is being transformed impact the fair use analysis, so to does the nature of the transformed work; e.g., whether the new work is parody or satire. The Campbell Court found that 2 Live Crew’s song was a parody of the Roy Orbison original and, therefore, was fair use. However, a satirical transformation may not be. The authors refer to Dr. Seuss Enters. LP v. Penguin Books USA, Inc.9, in which the Ninth Circuit found that defendant’s book The Cat NOT in the Hat! A Parody by Dr. Juice, which used “the rhyme scheme, thematic and narrative elements, and other identifiers of the original book, but it instead described the trial of O.J. Simpson” was not a parody of The Cat in the Hat, but was instead satire and not a fair use.
After looking briefly at whether the output of computer code-generating GenAI models could be fair use, the authors look at generated images, noting that “generated images, and generated art in particular, have their own complexities when it comes to fair use, with sometimes conflicting outcomes.” For example, the authors note that two different federal district courts came to opposite conclusions on whether it was fair use for video game makers to replicate the tattoos of real people depicted in video games.10
The authors next consider whether copying someone’s “style” could be fair use. This article was written before the Supreme Court issued its ruling in Andy Warhol Foundation v. Goldsmith, in which the Court held that Warhol’s painting (right image below) of Goldsmith’s photograph (left image below) was not fair use.11

The authors argue that
prompting generative models to illustrate something in someone’s art style is unlikely to create liability unless distinctive components of their art are re-used. For example, a prompt like “Campbell’s Soup Cans by Andy Warhol in the Style of Picasso” might be more risky if it recreates the original Warhol piece too closely. But a more generic style-transfer prompt like, “A random dog in the style of Andy Warhol” is more likely to be fair use (assuming, again, that the output itself is sufficiently transformative from Andy Warhol’s works).
While I agree that the output in the second scenario might be fair use, I think the training of such a model using Andy Warhol’s copyrighted works would not be fair use. That is, training a GenAI model using Warhol’s works that is then capable of creating a commercially viable image of “a random dog in the style of Andy Warhol” would almost certainly have an impact on the market for Warhol’s existing works, which is both one of the enumerated four factors and sometimes dispositive where the economic harm to the original work from the new work is obvious.
The recent Blurred Lines case shows courts’ willingness to look at “style” as a protectable element of a song. In that case, the Ninth Circuit upheld a jury verdict that Pharrell Williams and Robin Thicke's song “Blurred Lines” infringed on Marvin Gaye's 1977 hit song “Got To Give It Up.” But Blurred Lines did not copy the notes or lyrics of Got to Give It Up. Instead, the jury found that Williams and Thicke copied the “feel” or “style” of Marvin Gaye.12
The rest of the article discusses potential technical mitigation efforts to reduce the likelihood that GenAI models infringe. These include not training models on copyrighted content, which the authors acknowledge “may not be possible for many practical settings,” output filtering, which the authors acknowledge doesn’t work so well and it easily bypassed, instance attribution, which the authors acknowledge suffers “from difficulties in scaling due to high computational cost,” differentially private training, which THIS AUTHOR admits he needs to better understand, and learning from human feedback, which seems nearly impossible to implement at scale.13
“Foundation models are machine learning models trained on broad data (typically scraped from the internet) generally using self-supervision at scale. Most foundation models are not trained to accomplish specific tasks but rather to capture useful general information in the data.”
Notwithstanding the provisions of sections 106 and 106A, the fair use of a copyrighted work, including such use by reproduction in copies or phonorecords or by any other means specified by that section, for purposes such as criticism, comment, news reporting, teaching (including multiple copies for classroom use), scholarship, or research, is not an infringement of copyright. In determining whether the use made of a work in any particular case is a fair use the factors to be considered shall include—
(1) the purpose and character of the use, including whether such use is of a commercial nature or is for nonprofit educational purposes;
(2) the nature of the copyrighted work;
(3) the amount and substantiality of the portion used in relation to the copyrighted work as a whole; and
(4) the effect of the use upon the potential market for or value of the copyrighted work.
The fact that a work is unpublished shall not itself bar a finding of fair use if such finding is made upon consideration of all the above factors.
See, e.g., Asay, Clark D. and Sloan, Arielle and Sobczak, Dean, Is Transformative Use Eating the World? (February 11, 2019). 61 Boston College Law Review 905 (2020), BYU Law Research Paper No. 19-06, Available at SSRN: https://ssrn.com/abstract=3332682 or http://dx.doi.org/10.2139/ssrn.3332682.
N-gram overlap refers to the similarity between two sets of n-grams, which are contiguous sequences of n items (typically words or characters) from a given text. This measure is often used in natural language processing and text analysis to compare the similarity between two texts, where an n-gram of 0 means no overlap of characters and 1 means complete overlap.
Compare Alexander v. Take-Two Interactive Software, Inc., S.D. Ill. 2020 with Solid Oak Sketches, LLC v. 2K Games, Inc., S.D.N.Y. 2020.
The authors describe how this process might work as follows:
human annotation frameworks in these approaches can take into account the copyright implications of rating systems and instruction following, particularly when incorporating human feedback at scale. For example, in current feedback-based learning mechanisms, human labelers are asked to rate model generations based on a Likert scale or pairwise comparisons. A method for learning a reward function that both maximizes the capability of the model and respects fair use could add an additional question, where human labelers would be provided with the closest copyrighted content and asked to flag any content that is not sufficiently transformative from the copyrighted material. Models can then be trained with this feedback incorporated.